Learning to Play Tic-Tac-Toe using Q-table and Neural Network:


Key Take-away: Q-table used in Q-learning is a brute-force method to learning a particular skill, however it is memory intensive and impractical. On the other hand, neural network …
Details:
Game overview: A game of Tic-Tac-Toe has easy rules: get three X or O in a row, column or diagonal to win. If the players run out of space, it is a draw. For teaching the same to a computer, Q learning – a machine learning algorithm is used.
Methodology: The Q-table used in Q-learning is built by self-play, where the player 1 (X) is learning to optimize its play by playing against player 2 (O). Policy for both players is through the same Q-table, that is, to have the player play against itself to win the game. Each game begins with an empty board and stops when either player wins or the game is draw. The learning does result in optimal policy as both players have equal chance at winning and if none wins then it is a draw. The approx results over multiple trials has been: player 1 and 3 wins approx. 40% of the time and it is draw remaining 20%.
Q-table is good for learning in the examples with limited state space. However, it requires lot of memory space and it is not salable in complex problems like, chess, etc. I have implemented the same problem of tic-tac-toe using Neural networks. In the implementation, the Q-table has been replaced with a functional approximation Neural network. All other factors are same. It takes approximately 50000 for the Neural Network to converge to either 100% draw or 50% win for both players. In the above animation, we can see the human players wins when the model is trained for 2000 trails and it draws when trained for 50000 trails.
Balancing an Inverted Pendulum
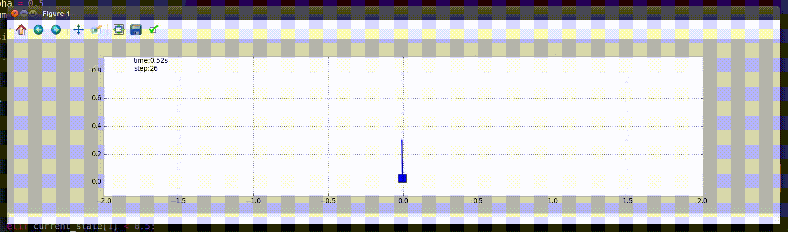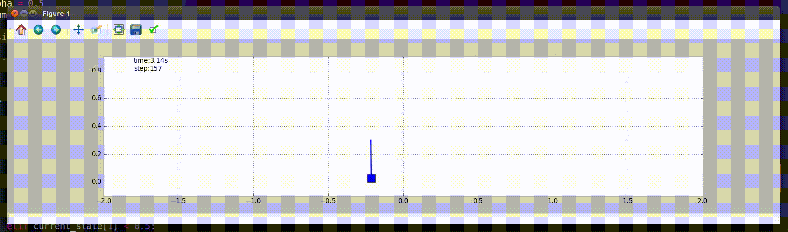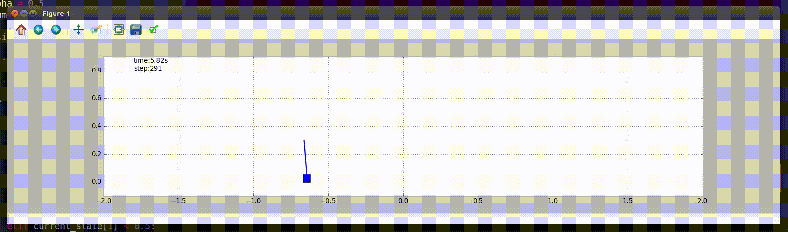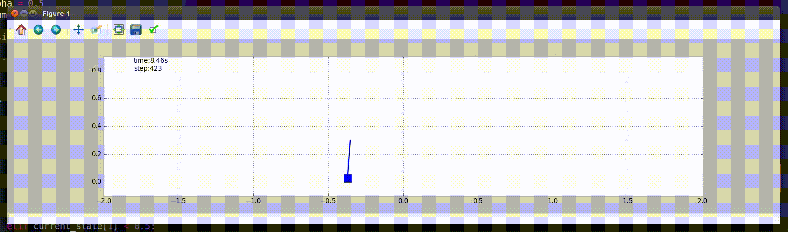
The task is defined as balancing an inverted pendulum on a cart in an upright position. The method chosen for this task is a machine learning algorithm: Q-learning. It is a method, that doesn’t require knowledge of model for learning. It learns by experiencing the reward for taking a sequence of action. For more information, please read the following document – PDF.
